
HAProxy ve Keepalived ile H/A Load Balancer Kurulumu
Çeşitli ortamlarımızda Load Balancer ihtiyacımız olabilir. Örneğin ben on-premise Kubernetes ortamında ingress controller'a trafiği yönlendirmek için kullanmıştım. H/A için Yazılımsal Load Balancer güzel bir çözümdür fakat tek bir LB ortamımızda single point of failure oluşturmaktadır. Yani ne yapalım LB önüne bir LB daha mı koyalım gibisinden kötü bir espri yapmadan anlatıma geçiyorum 🙂
Öncelikle 2 adet VM, 3 adet IP adresine ihtiyacımız var. Ortam aşağıdaki gibi olacaktır.
192.168.4.60 - VIP
192.168.4.61 - LB1
192.168.4.62 - LB2
İki adet LB nodumuz aktif-pasif çalışacaktır. VIP ip adresimiz Floating IP olacaktır. Yani LB1 nodumuz down olduğunda otomatik olarak LB2 noduna tanımlanacaktır. Böylelikle trafiğimizi yalnızca Floating IP'ye yönlendirerek arkada 2 adet node ile H/A bir yapı kurmuş olacağız. Şimdi kuruluma geçelim.
Öncelikle LB1 ve LB2 nodelarımıza KeepAlived ve HAProxy kuruyoruz.
# yum install -y keepalived # systemctl enable keepalived # systemctl start keepalived # yum install -y haproxy # systemctl enable haproxy # systemctl start haproxy
LB1 nodumuz aktif, LB2 nodumuz pasif çalışacak. Öncelikle bu iki sunucuda KeepAlived konfigürasyonu yapıyoruz.
vim /etc/keepalived/keepalived.conf
### ADD
vrrp_script chk_service_status {
script "/usr/local/bin/haproxy-service-check.sh"
interval 2
fall 2
rise 2
timeout 2
weight 5
}
vrrp_instance VRRP1 {
state MASTER
interface eth0
virtual_router_id 66
priority 101
advert_int 1
authentication {
auth_type PASS
auth_pass Rgs451dw
}
virtual_ipaddress {
192.168.4.60
}
track_script {
chk_service_status
}
}
###
Şimdi bu configi biraz açıklayalım. En üstteki vrrp_script kısmında haproxy-service-check.sh diye bir script çalıştırdık. Neden yaptık bunu? Şöyle ki teoride LB1 nodumuz down olduğunda VIP IP pasif olan LB2 nodumuza tanımlanıp trafiği karşılamaya devam edecek fakat LB1 nodumuz down olmadan loadbalancing işlemini yaptığımız HA Proxy servisimiz down olabilir. Burada biz bunuda kontrol etmeliyiz ki tam anlamıyla H/A bir yapı oluşturabilelim.
vrrp_instance > state kısmı LB1 nodumuzda MASTER olacaktır.
vrrp_instance > priority kısmı 101 olacak.
vrrp_instance > authentication kısmında bir password belirliyoruz.
virtual_ipaddress kısmına da VIP ip adresimizi yazıyoruz.
Sonrasında HA Proxy'nin aktifliğini kontrol ettiğimiz scripti ekliyoruz.
# cat > /usr/local/bin/haproxy-service-check.sh <<EOF
#!/bin/sh
SERVICE=haproxy
STATUS="$(pidof $SERVICE | wc -w)"
if [ $STATUS -eq 0 ]
then
exit 1
else
exit 0
fi
EOF
# chmod +x /usr/local/bin/haproxy-service-check.sh
LB1 nodu için yapılandırma bu kadar. Şimdi benzer işlemleri LB2 nodu için yapıyoruz.
vim /etc/keepalived/keepalived.conf
### ADD
vrrp_script chk_service_status {
script "/usr/local/bin/haproxy-service-check.sh"
interval 2
fall 2
rise 2
timeout 2
weight 5
}
vrrp_instance VRRP1 {
state BACKUP
interface eth0
virtual_router_id 66
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass Rgs451dw
}
virtual_ipaddress {
192.168.4.60
}
track_script {
chk_service_status
}
}
###
vrrp_instance > state kısmı LB2 nodumuzda BACKUP olacaktır.
vrrp_instance > priority kısmı 100 olacak.
vrrp_instance > authentication kısmına LB1 nodunda belirlediğimiz şifreyi yazıyoruz.
virtual_ipaddress kısmına da VIP ip adresimizi yazıyoruz.
Sonrasında LB2 nodumuza da HA Proxy'nin aktifliğini kontrol ettiğimiz scripti ekliyoruz.
# cat > /usr/local/bin/haproxy-service-check.sh <<EOF
#!/bin/sh
SERVICE=haproxy
STATUS="$(pidof $SERVICE | wc -w)"
if [ $STATUS -eq 0 ]
then
exit 1
else
exit 0
fi
EOF
# chmod +x /usr/local/bin/haproxy-service-check.sh
Evet, KeepAlived tarafında kurulum bu kadar. HA Proxy tarafında her iki nodumuzda da aynı konfigürasyonu yapıyoruz. Ben örneğimde daha önce de belirttiğim gibi dışarıdan trafiği Kubernetes workerlarımın 80 ve 443 portuna balance ettiğim konfigürasyonu kullanıyorum.
# cat >> /etc/haproxy/haproxy.cfg <<EOF frontend haproxy_stats bind *:8080 stats uri /haproxy?stats frontend http_front bind *:80 mode tcp default_backend http_back backend http_back balance roundrobin server worker1 192.168.4.66:80 check server worker2 192.168.4.67:80 check server worker3 192.168.4.68:80 check server worker4 192.168.4.69:80 check frontend https_front bind *:443 mode tcp default_backend https_back backend https_back mode tcp balance roundrobin option ssl-hello-chk server worker1 192.168.4.66:443 check server worker2 192.168.4.67:443 check server worker3 192.168.4.68:443 check server worker4 192.168.4.69:443 check EOF
Son olarak servislerimizi restart ediyoruz.
# systemctl restart keepalived # systemctl restart haproxy
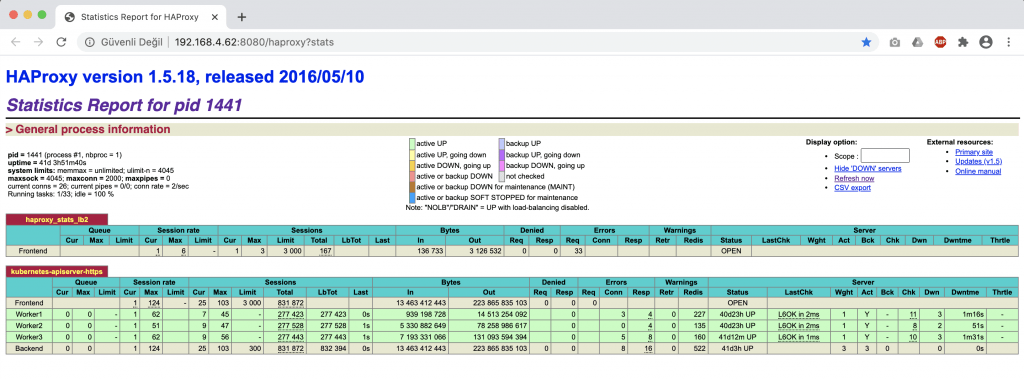
Tarayıcıdan aşağıdaki adreslere giderek LB1 ve LB2 nodelarımızın durumlarını görebiliriz.
http://192.168.4.61:8080/haproxy?stats
http://192.168.4.62:8080/haproxy?stats

Hola! Ben Ali. Hepsiburada’da DevOps Engineer olarak çalışmaktayım. Microservis mimarisine özgü altyapı tasarlamayı, kurmayı ve operasyonel süreçlerini yönetmeyi seviyorum. Ayrıca şu sıralar GO Lang öğrenmek için de emeklemekteyim.
Selamlar.
Merak ettiğim 2 husus var, bu 3 sunucu aynı datacenterda olmak zorundamıdır? Yani 3 sunucu 3 farklı lokasyon veya 3 farklı datacenter da kurulu olsa problem olur mu?
Birde mesela yük dengeleme amaçlı kullandığımız bir sunucuda video içeriği var diyelim, bunu ana sitede nasıl yayına sokabiliriz? Video kaynağı olarak sunucu ip adresimi görünüyor yoksa site adresimi?
Teşekkürler şimdiden, Hayırlı Günler, bol kazançlar dilerim.
Selamlar, farklı datacneterlardaki sunucular birbirine erişebildiği sürece clustered yapıya kavuşturulabilir fakat bu sunucular arasında data transferi gerçekleşiyorsa verimerkezleri arasındaki latency az ve stabil bir network bağlantısı kurulması önemlidir. İkinci sorunuza yanıt olarak loadbalancerlar zaten, sunulacak datayı barındıran N tane sunucuya tek bir ip veya domain ile erişmek için konumlandırılmaktadır.
Merhabalar,
Ali Bey elinize saglik cok faydali bir yazi.
Sanirim, keepalived.conf dosyasinda kontrol scripti olarak chk_service_status verilmis.
Fakat orneginizde servisi haproxy-service-check.sh ismi ile /usr/local/bin icine olusturuyoruz. Bu config her timeout suresinde gereksiz yere sanalip adresinin nodelar arasinda gezmesine sebep olabilir.